I tested a DGX Spark against my M3 Max for local AI. The Mac won the obvious benchmark. I'm keeping the Spark anyway.
I added an NVIDIA DGX Spark (the GB10 Grace-Blackwell box, ~122 GiB of usable unified memory) to a desk that already had an Apple M3 Max with 128 GB. Instead of quoting the launch-day tokens-per-second number everyone quotes, I spent an acceptance trial on one question: does this thing earn its place next to a laptop I already own?
Short version: at the benchmark most people run first, single-user text generation, the Mac wins, and the gap grows as models get bigger. That isn't a defect, it's memory bandwidth. It's also not what the Spark is for. The box earns its keep somewhere else: mixture-of-experts models, batched serving, CUDA fine-tuning the Mac's stack can't do, and always-on local work at roughly the power of a light bulb.
Everything below was measured on my own two machines. Every accuracy number is on synthetic documents only — no real, personal, or client data. (One exception: the fine-tune trained on a private internal text corpus I'm not shipping or describing. That's a throughput result, not an accuracy claim.) The inference numbers are recomputable from the raw JSONL in a public repo, alongside the exact commands, the limitations, and a page of objections I'd raise myself — the synthetic-workflow artifacts stay private (domain-sensitive), so those you get as reported numbers plus the recipe. Check what's checkable instead of trusting me.
This is not a universal Apple-vs-NVIDIA benchmark. It's one bounded question: given this Mac and this Spark, which finishes these jobs faster, which stack exposes the standard CUDA fine-tuning path, and what breaks during real use. Don't generalize the numbers past those conditions.
The inference map: dense loses, MoE is murkier than I expected
All of these are Ollama single-stream decode on bit-identical GGUF weights (content-addressed, copied between the machines), median of three after warmup, unique prompt per request so nothing gets inflated by a warm cache. One confound I only characterized in final review: the two machines were on different Ollama builds (Mac 0.23.0, Spark 0.30.11) — identical weights, non-identical engines. The bandwidth story below is physics and survives that; the exact percentages could shift a few points under matched builds, and the planned re-run pins versions.
| Model | Type | M3 Max | DGX Spark | Winner |
|---|---|---|---|---|
| qwen3:4b | dense | 81.6 t/s | 80.3 t/s | tie |
| qwen3:8b | dense | 54.1 t/s | 43.7 t/s | Mac +24% |
| qwen3:14b | dense | 35.2 t/s | 23.9 t/s | Mac +47% |
| qwen3-coder:30b | MoE (3B active) | 77.2 t/s | 91.2 t/s | Spark +18%* |
| deepseek-r1:32b | dense | — | 10.5 t/s | (Spark, slow) |
| llama3.3:70b | dense | — | 4.8 t/s | (Spark, patient) |
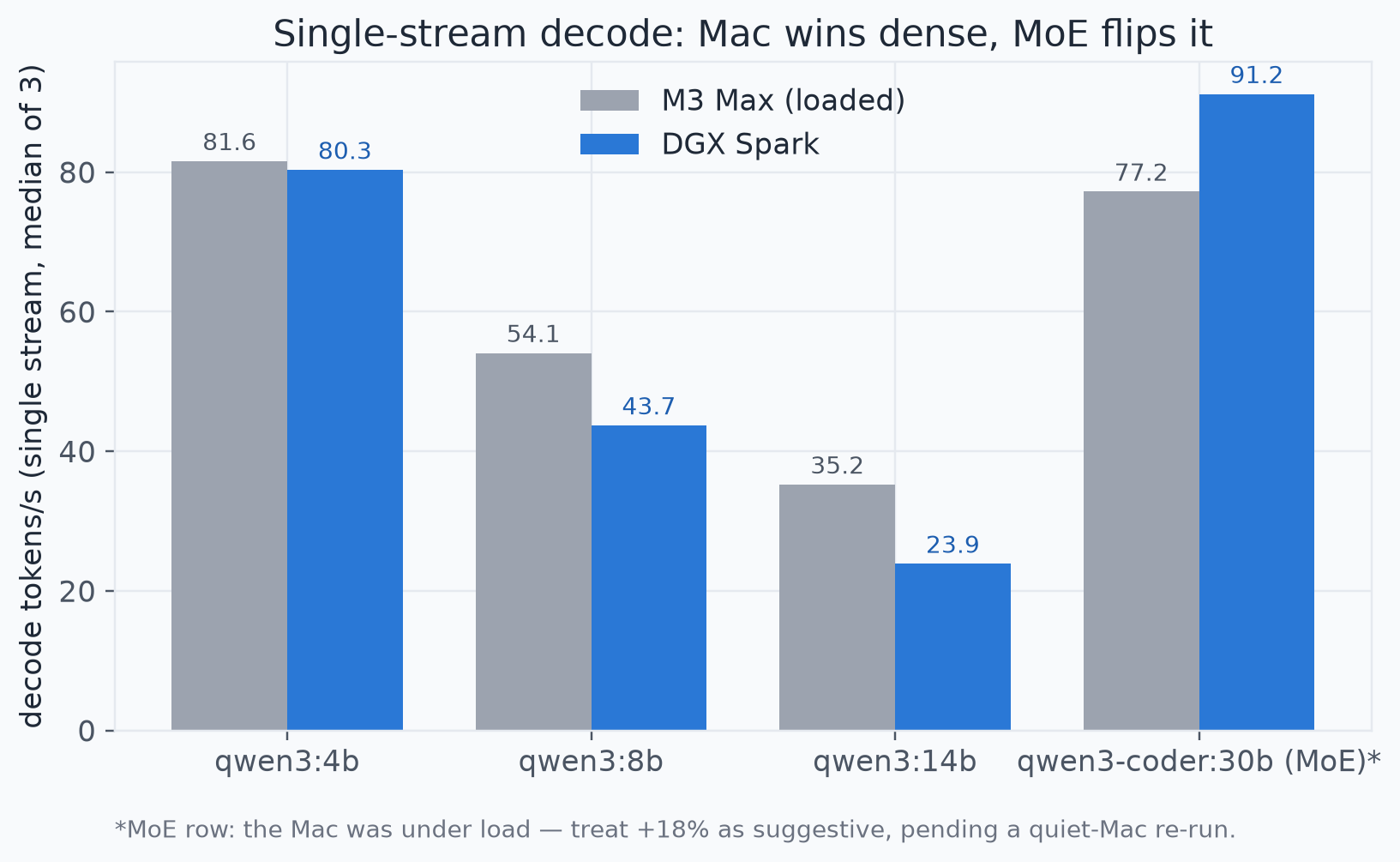
The dense pattern is clean, and it's physics. Single-stream decode is memory-bandwidth-bound. The Mac's ~400 GB/s spec beats the Spark's 273 GB/s spec, and the gap widens with size: the Spark/Mac ratio falls 0.98 → 0.81 → 0.68 going from 4B to 8B to 14B. You can't flag your way around a bandwidth wall.
Then the MoE model flips it. qwen3-coder:30b only activates 3B parameters per token, so it's far less bandwidth-bound, and the Spark comes out 18% ahead.
That asterisk, though. I want you to see this caveat before you quote the number: my Mac figures were taken while the Mac was under load, on that older Ollama build. For the dense rows that only makes "the Mac wins" more true — a quiet Mac wins by more. For the MoE row it cuts the other way. A fully idle Mac might narrow that +18%, maybe erase it. Treat "MoE is the Spark's lane" as suggestive, pending a quiet-Mac re-run. Not settled. I'd rather tell you that now than have you cite a number I don't fully trust yet.
The 32B and 70B numbers (10.5 and 4.8 t/s) look grim until you reframe them: that's a big model resident 24/7, grinding an overnight queue at tens of watts while I sleep. Slow tokens on an always-on box are a different economic good than fast tokens you have to sit and watch.
Where the Spark actually earns its place
Batched serving. Run the same box under vLLM with NVFP4 weights and continuous batching and aggregate throughput scales about 10× — 37.5 tok/s at one stream to 381.7 tok/s at 32. Per-request speed drops (37.5 → 13 t/s) and time-to-first-token climbs, but for a queue (extraction batches, agent calls, overnight jobs) aggregate is the number that matters. (I didn't capture per-run wattage in this dataset, so no power claim here.) And to be clear about the landscape: this is not a discovery. Others have pushed Spark concurrency much further: Dendro Logic measured ~120× at 256 streams. Mine is a confirmation at small batch. The point stands either way: serving many requests at once is the thing a laptop's Metal stack structurally can't do, and it's exactly what this box is for.
CUDA fine-tuning. The strongest argument for the Spark, and it gets its own post. In my first head-to-head run, same data and step budget, the Spark finished roughly 3× faster than Apple's MLX on the Mac. I'm deliberately not bolding that number yet: the first run's LoRA configs weren't bit-identical, I didn't record the Mac's load state during its leg, and a fine-tune benchmark that isn't matched knob-for-knob isn't a benchmark. I've since re-run the CUDA side three times under a locked, matched config (σ ≈4% of the mean); the matched MLX side runs as soon as I can give the Mac a genuinely idle window, and the final number lands in the dedicated post with the full parameter table. What I will say flatly now: the Spark runs a 4-bit QLoRA path the Mac's stack doesn't expose at all, and that — not the speed ratio — is what puts 30B and 70B fine-tunes within reach.
Doing real work locally, on synthetic data. Two workflows, both on synthetic documents.
Field extraction — pulling five typed fields out of 50 synthetic documents with qwen3:14b — hit 96.8%. The gotcha that got me there is at the bottom of this post, and it's the single most useful thing in this writeup.
Local retrieval-augmented Q&A over 100 synthetic documents is the more interesting result, and I'm leading with its weakness because that's what makes the strengths believable: retrieval precision was only 22.7%. The right documents were almost always in the candidate set (recall 88.9%), they were just buried in junk. Textbook "add a reranker" problem. Given that weak retrieval, though, the generation layer did the two things that actually matter for high-stakes local use: it invented zero sources, and it correctly refused all 13 unanswerable questions. The trust layer held up even while the retrieval layer needs help. (It also refused about 2% of answerable questions; worth knowing before you deploy something like this.)
The reliability traps the short reviews miss
The "no throttle" verdicts you've read are inference verdicts. Training is where the box gets in trouble.
Credit where it's due: owners found this before I did. NVIDIA's own forum has threads documenting shutdowns where the CPU hits ~95 °C while the GPU sits around 82 °C. The failure is CPU-side. If you only watch the GPU sensor, you never see it coming. What I can add is measurement: I ran a sustained 8B LoRA fine-tune with a 30-second thermal logger on my own unit — a 23.9-hour logged span, ~22.4 hours of it under load. The CPU zones climbed slowly for about 20 hours (77 → 85 °C average), then plateaued at ~85 °C, 88 °C peak, for the final four hours — zero throttle, zero shutdown, GPU between 66 and 84 °C, clocks never below 2411 MHz under load. So the shutdown risk is real and it's CPU-side. On this workload my box peaked about 7 °C under the ~95 °C reports, and only ~3 °C under the coolest reported crash at 91 °C. A real margin, but not one an 8B LoRA in a temperate room earns much credit for. The full curve, the owner-converged clock-cap mitigation, and the one competing theory about what's actually killing these boxes all get the dedicated thermal post.
The bigger 24/7 risk isn't heat at all. It's the unified-memory OOM hard-wedge: push memory too far and the whole host freezes until you physically power-cycle it, and — this genuinely surprised me — a container's cgroup memory limit does not save you, because the wedge happens below the container. If you're going to leave this box running jobs unattended, run earlyoom and keep a second SSH session open as a lifeline.
One power correction while I'm here: the 7–11 W figure everyone quotes is bare idle. Loaded and working, this box lives in the tens of watts. Still remarkable; just not single digits.
The one gotcha that will save you hours
If your local model returns empty JSON for structured extraction, this is almost certainly why: reasoning models ignore an in-prompt /no_think. You have to pass "think": false in the API call itself, or the model spends its entire token budget thinking and hands back nothing. Flipping that one flag is what moved my extraction from unusable to 96.8%. (I don't have a saved trace of the exact starting number, so I'll just say it was near-unusable and leave the precise figure out.)
So — keep it or send it back?
If you want the fastest single-user chatbot, buy a laptop with more bandwidth. The Spark loses that race and loses it harder as models grow.
But that was never the right question. The Spark earns its place as a second, always-on node. It holds the big models so the laptop stays a laptop. It fine-tunes on local data in ways the Mac's stack can't. It serves a batched queue. And it does all of it at home, at roughly light-bulb power, with nothing leaving the house. Judge it on tokens-per-second and you'll send it back. Judge it on tokens-per-day, jobs-per-night, training you couldn't otherwise do, and data that stays yours — and it stays.
All numbers measured on my own hardware; workflow accuracy on synthetic documents only. Raw data, commands, and the objections I'd raise myself are in the repo — corrections welcome, and they get logged.